Artificial Intelligence: The Good, the Bad, and the Ugly - Yaser Abu-Mostafa

[Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] [Music] Good evening. I'm Harry Atwater. I serve as Chair for the Division of Engineering and Applied Science at Caltech and I want to welcome you all here, those of you here in Beckman Auditorium and those of you also viewing virtually online, to this final lecture of this year's Watson Lecture series. And we're in for a special treat tonight. I'll just note that this is the Centennial year of the Watson Lectures and for 100 years, this lecture series has been educating and providing thought-provoking perspectives on STEM - Science, Technology, Engineering and Mathematics - for a public audience. And so, that's quite a long record. I'll mention that tonight's speaker is celebrating his 40th anniversary as a Caltech faculty member. Professor Yaser
Abu-Mostafa, who is a Professor of Electrical Engineering and Computer science, began his career as an Assistant Professor and he's been here at Caltech ever since 1983, both teaching and doing research in the subject of tonight's lecture: Artificial Intelligence and Machine Learning. And this is a subject that actually has a long history dating back to the seminal and conceptual events that led to the invention and development of neural networks during the 1970s and 1980s, which are many of the foundations as Yaser will tell us about for Artificial Intelligence. I want to say also a special thanks to the Friends of the Beckman Auditorium for their kind and enduring support for tonight's lecture series, and in particular the support that they've made available in supporting and hosting students from the partnership to uplift communities Early College Academy for Leaders and Scholars. So we're happy to have you here tonight. [Applause] And I'll simply say that when I became division chair about two years ago, we had a discussion among the department chairs and faculty about some of the most important science and technology trends emerging as the basis for developing a strategic plan for the division. And number one
on our list of priorities is being able to broaden the use of AI and Machine Learning all across the research and teaching portfolio of Engineering and Applied Science at Caltech. And of course this has really rocketed into our public gaze and public attention over the last few months with the development of amazing new tools. So tonight's speaker, Professor Yaser Abu-Mostafa has done research and as I mentioned literally wrote the book; He wrote a seminal textbook and has taught massive open online courses - MOOCs - on this subject, and is well known for his teaching both the Caltech students and to broader audiences. He's not going to share a lot about this tonight, but his own research is also focused on the use of AI and Machine Learning in a variety of technology applications, including medical applications like non-invasive technologies for monitoring the bloodstream to mitigate and prevent strokes, among others. So, that's a good
application of Artificial Intelligence. Yaser is going to tell us the whole story: Artificial Intelligence, The Good the Bad, and the Ugly. Professor Abu-Mostafa: [Applause] [Music] My father worked in Aeronautics and at the time he worked, all the good results came from Caltech. So, it became completely obvious that I wanted to come to Caltech when I was like seven or eight years old.
When I came to campus, the campus struck me as beautiful, relaxed. You have lots of room to think, to research, to imagine. This is exactly where I want to be and how I want to work. I spent two thirds of my life at Caltech This is my home. So, it's completely the environment where I can be productive and where I want to help. Where I want the students
to flourish, where I want good things to happen. It's almost a selfish thing for me, because that's my home. I'm Yaser Abu-Mostafa. I am a Professor of Electrical Engineering and Computer Science at Caltech, and my specialty is Artificial Intelligence and Machine Learning. You know, you go back to the Industrial Revolution - you know it used to be that we lift heavy stuff, we lift heavy stuff, etc. And then there were the machines, and we stopped lifting heavy stuff. Nobody is complaining now that
there are these machines that, you know, lift a lot of things. Construction workers don't have to do the lifting, but they actually do very intelligent stuff in order to make a building out of the stuff that has been lifted. It's a little bit more difficult to imagine in Artificial Intelligence because it touches on something that we consider ours. We are the intelligent, you know,
entity. But there is really no competition at this point. It's just that we are unloading some of the routine tasks that, although they require some intelligence, they are boring. We are driving a car, I'm going somewhere, I'm driving for 50 miles on the freeway. Tons
of intelligent decisions I'm making all the time, but I'm not enjoying any of them. I want to arrive. If someone can do this for me, thank you very much! I will now try to, you know, dedicate my time to something more imaginative, and whatnot. One of the questions is how far can we go? The jury is out. There is no question that we don't know where it goes. You keep thinking about something, you keep thinking about the other angles, something is bothering you, something is unsolved. Sometimes, when you are working
on a problem, it's just too agitating. So, you just want to go somewhere and unwind. I take walks at night where I sit down on a bench. It's quiet, it's at night, I can see students going by, etc. I am relaxed. This is as wonderful an experience as one can have. I can honestly say that
it's exactly that - you know the cartoon where there is a light bulb - it just happens. When all is said and done, when you are completely involved in an idea and you bring it from vagueness to concreteness to becoming a product, and you stumble into things that you didn't expect, you have an understanding that you didn't think of, there is nothing more enjoyable in my life. Chocolate is a close second, [Laughter] but that is OK! [Music] [Applause] Good evening, everyone. Welcome to Caltech. Tonight, I'm going to talk about Artificial Intelligence. It's a subject
on everybody's mind nowadays, sometimes with excitement and sometimes with apprehension. One of the reasons for the apprehension is that AI was able to achieve human-like performance recently, and we did not expect a machine to do that, so we are a bit mystified. And we don't know exactly what else it can do.
So, a big part of the lecture today is to demystify AI. I will take you step by step through the science of AI, in a way that everybody can understand. Because once we understand it, we can address the questions of policy, impact on society in a meaningful way. So the outline is simple. First, we are going to talk about how AI actually works.
Then, we are going to talk about what AI can do for us. Then, we are going to talk about what AI can do to us [Laughter] Let's start with the science. I think the most important message is to understand how a machine can show symptoms of intelligence. If I can
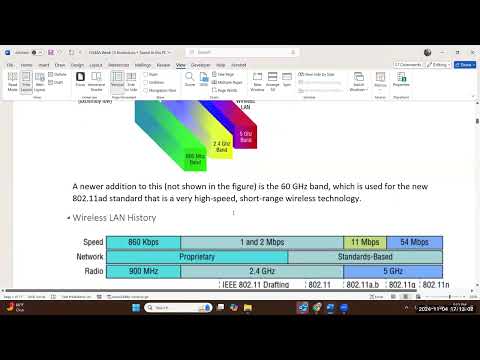
convince you of that, probably the rest is easy. And I can do that by looking back at an earlier version of Artificial Intelligence. This was in the era of expert systems, which happened before neural networks, and it's a brute-force approach to Artificial Intelligence. So, how does that work? Well, you have a lookup table. Let me tell you
what a lookup table is. A lookup table is a giant cheat sheet. So, you have this enormous cheat sheet, it has all the information written into it, and you have a quick way of looking up the answer you want.
So, someone asks you a question, you quickly look, you find the answer, and you answer it. So, you look very smart to them because you have the answer to everything. And this very simplistic brute-force approach to Artificial Intelligence led to actually wonderful achievements more than 10 years ago. If you remember those. So, AI here was able to beat the all-time champion of Jeopardy. And before it, AI was able to beat the world champion in chess.
Now, these are great achievements, but they are easy to understand. Because humans can only store that much information. Machines can store encyclopedias upon encyclopedias. and search them very
quickly, so humans don't have a chance. On this side, humans, chess experts, can look ahead five moves, eight moves, and plan accordingly. Machines can look 12 moves, 15 moves, so humans don't stand a chance.
So, in both cases, you were able to have the appearance of intelligence - and actually super intelligence - just by doing it by brute force. Now, this is not the current mode of intelligence that we're observing in the AI systems. What we have now is much more flexible than this. Those things required full teams from IBM to work for years. And after all of this great work
and the hand-tailored design of the system, and putting the information in the right place, and whatnot, these guys were used exactly once. They beat the Jeopardy champion and retired, and they beat the chess champion and retired. Definitely, this is not the mode we want. We want something, first, that does not require an enormous effort to build. So it has to be able to automatically get into the task that we want.
We want it to be more broad and more flexible, not just play Jeopardy or play chess. We want it to exhibit more symptoms of intelligence. And that is the biggest change that happened in the 1980s that made us move from the brute-force approach to the learning approach. So, let's see how this works. Well, here we are, this is our brain, we are smart. Nobody goes into our brain and
puts in pieces of information at the right place, right? What happens is that we get data coming in, completely unstructured, and then we have a learning rule that takes all of the incoming sensory information and is able to learn from it, such that we become smarter and smarter and more knowledgeable. And the learning algorithm is built in. And if you go into the details of it, it's a remarkably simple learning algorithm. You have a synapse that is sandwiched between two neurons and depending on what happens, either the strength of the synapse goes up or down.
So, you ask yourself how could we become intelligent by something that simple? Well, that's one synapse, right? This fellow has 100 trillion synapses or more. So, you can see that you can store tons of information, and it's organized in a way that the recall and the learning is very easy. Now, the main point here is that learning is absolutely essential to intelligence. That is, before we learned, we did not exhibit any symptoms of intelligence, and the data coming in didn't make any sense at all. And here's the evidence [Laughter] So, data comes in, we learn. The message here is important because you may have been hearing about Machine Learning / Artificial Intelligence, and you wonder what is the difference, etc.
Now, the ... The way this works is the following. Machine Learning is used almost synonymously with Artificial Intelligence nowadays because of the following.
Machine Learning is what we do. Artificial Intelligence is what we achieve. That's why they are used interchangeably. OK, so now, knowing that, let's see how to imitate the brain in order to be able to get to the intelligence. in the 1980s, we started building models that try to mimic aspects of the brain, instead of doing the brute-force approach with big computers that store lots of information as in expert systems.
So, we look under the microscope and you see neurons connected by synapses. So, we extracted that, and we now have "neurons" connected by synapses. They are heavily connected. And hoping that this
system together with a learning rule that is close to what is happening here - not exactly the same but close - will be able to simulate the function that is of intelligence. Now, at that point in time, it looked far-fetched. However, it took a lot of patience, stick-to-it-iveness and whatnot in order to be able to get to the level where this actually works. And we had precedents in biology. We get inspired by biology in order to do many functions that we would like to do. So, another example which is very simple is flying.
We would like to fly so you look at, you know, around. You see birds fly. Let's try to imitate them. So, the idea here was to extract enough of the essence of flying, which in this case wings and maybe tails, and whatnot. You are not trying to mimic biology exactly. You are trying to extract the essence. And, as you realize, we have
flying machines that are wonderful, but they don't flap their wings, right? So, once you get the essence, the rest is technological development. Here, you do partial differential equations and conformal mappings and all of this fun stuff. Here, you do learning algorithms that work with that, different architectures in order to be able to deal with different things. It's a technological development.
So when you ask yourself: did we abstract the essence that the neurobiological systems have that reflects intelligence by just doing that? in the 1980s, we had no idea. It was an article of faith. Nowadays, we can say a definitive yes. You have seen it in the latest applications of AI.
So, here is the magic neural network. This is the basic model of neural network. So, you have the neurons connected by synapses. And I'm drawing your attention to the synapse, or the parameter. So, this is called the parameter, or synapse in biology, OK? And there are, you know, tons of parameters. ChatGPT has 150 billion
parameters. So, it's a completely different scale. Here, maybe you have 100 parameters. So, the best way to understand them is to think of the parameter as a knob.
So, you try to learn a function. You have tons of knobs, and you are trying to tune them according to the incoming data in order to make your neural network perform the function you want. So, it's a giant task, but the good news is that we have a learning algorithm that tells you how to adjust this, as data comes in, such that when you are done the setting of the knobs, all 150 billion of them, is such that the network does the job you want. The model you are looking at is the basic neural network. There are many other models of neural networks. For
example, the one that is used in GPT is called the Transformer. That's the T in GPT, and it's a pretty clever model that has a very nice mechanism for attention. And the best way to understand the different models is to look at the brain. Different parts of the brain have different structures, right? They have different functions. So, while the building block is the same, the neurons and the synapses and the learning algorithms that goes with them, there is a great benefit from making particular models that are tailored toward particular tasks. And that is what happens with these models.
OK. Now, we look at the contrast between the older version of artificial intelligence and the newer version of artificial intelligence in terms of the information storage. How do you put the information into this? I told you that you don't go and insert something into your brain, and indeed you don't. In the expert systems, you actually go and insert the information and search for it. So I'm going to give you an
example. Let's say that you design the system, either expert system or a neural network, to answer different questions. Here's the question you ask. So, how does the expert system work there? Well, the expert system is already pre-programmed. "Oswald" is sitting
somewhere. All you need to do is search the database in order to find the right answer, and then out comes the right answer. When you come to neural network and ask it the same question, who killed Kennedy, it's very interesting to look how information is stored. This is a caricature of how it is stored. It's all over the parameters. Many pieces of information that interact in the parameters, and when all is said and done, they give you the answer.
There is a great advantage of having these micro pieces of information spread all over the parameters, coming from the answers to many many questions, not only this question. Because that gives you a way for the pieces of information to softly collaborate and be able to extrapolate to questions that you haven't seen yet. It's much softer than in the case of expert systems. Expert systems are brittle. You ask me a question, I go for
the answer, I find the answer, I tell you. I don't find the answer, I don't quite know what to do. Here, you ask a novel question, there is so much information that are distributed that if you perturb it a little bit you get something meaningful.
So, this is a great advantage, but it also answers one of the questions that are often raised about Artificial Intelligence. You heard the problem that Artificial Intelligence is a black box. We can't explain what it does. We don't trust it. Right? Now, look at how it is structured. The information is spread in an extremely distributed way in small pieces. It is
very difficult to explain what exactly did the network do in order to come up with this answer. We know it, but what you really want when you say Explainable AI, you want a description of what it does in a succinct way. Here is what you do, and this is exactly what the network does.
Now, this is similar to if I ask you to do something, and you want to make a decision, and you have a gut feeling. And then you decide accordingly. Now, if I asked you could you please tell me why you made that decision, OK, what is a gut feeling? You probably can explain it a bit. There are certain factors that affect you, and what not. But if I want to pin you down in giving me exactly a legal document of why you did it, obviously that's not the case. And decisions made by gut feeling in our experience are actually pretty good in general, because they depend on lots of observations and lots of experiences that we accumulate over time. We may not be able to pin down
exactly the logical sequence we have, but we can get a decision. So, it is similar here. And indeed, because obviously explaining AI to some extent is important, there are technical methods to be able to explain what AI is doing partially. Not exactly, not to the last
detail. I can tell you what inputs it is using, which inputs result in a bigger signal or a smaller signal. I can do stuff like that, but if I fail to give you a full description of what the network is doing that fits in five lines, so that you can understand them, please realize that this is inherent. This is
how I built it in order to be able to be intelligent, and be able to learn and extrapolate to new situations. It comes with the territory. Another thing you must have heard is Discriminative versus Generative. And these are applications of neural networks that are very common. And there are, you know, other varieties but these are the big ones nowadays. So, let me
describe to you what they are. Both are neural networks. Both have inputs and outputs. But the nature of the inputs and
outputs are different. So, let's look at the Discriminative first. Well, you have a picture and you would like the network to tell you who this person is.
OK. That's why we call it Discriminative. You want to discriminate one person from another. So, the Network that has learned how to recognize faces comes and tells you this is Claude Shannon. Claude Shannon is the father of Information Theory by the way.
So, that's Discriminative. Let's look at the other side, which is Generative. The input is actually very simple. Here, the input is a full image and whatnot.
The input there is very simple. You just have a query or a request. Create a face! So, the network goes and creates a face for you. And this is not the picture of a person, remarkably as this may sound. This is something that the neural network dreamed up based on your request.
And you can see the different applications for these guys. So this side, you know, you can generate art. Maybe soon, we will generate entire movies, you know. Give me a nice movie about this, this, and that. And out comes the whole movie. Maybe the Oscars will have to have a new category now for awards because of that.
On this side, this actually has lots of applications that impact our life greatly. For example, medical applications. Because in medical applications, you input in this case medical images, symptoms, observations. and out comes test results, diagnoses and whatnot. So, they are Discriminative largely. Both of these sides have great applications that will impact our life. Now, I'm going to spend a little bit to dig a little bit deeper into how neural networks work, because this is the way we can answer the questions about policy that, you know, are being debated out there.
So, when you are doing Artificial Intelligence, there is a phase where you are creating the network, and then there is a phase where you are using the network. And these are completely distinct, and have different implications. So, creating the network which is often referred to as training - these are the knobs I told you about. You have a network. It's not committed to any task. It's sitting on the, you know, surgery table. And you are working on it,
so that it becomes one network or another. Comes the data, you adjust the knobs, and after a while - quite a while - you end up with the task. Now, because this is a very elaborate process, it is very intensive computation. I'd like to give you some impression of how intensive it is. So, I
did back-of-the-envelope calculation about how long will my laptop take in order to be able to produce chatGPT from scratch, assuming that I have enough memory. That's a different issue, but let's say it has enough memory. I have a pretty decent laptop that I use for many many good applications, and I did the back-of-the-envelope calculation. How long do you think my laptop will take? Well, more than 200,000 years. [Laughter] So, it's just out of the realm of possibilities for anything. So now,
you can see how serious this is. Now, you can start believing this is really impressive. Well, it's impressive it took that much in order to train with 150 billion parameters, and all of this information and encyclopedias, and this and that. After all of that, you
better come up with something, and you come up with something very impressive in this case. The other aspect is that you realize that you are shaping the function from scratch here. You can teach the network whatever you do. AI has no intentions, no good intentions, no bad intentions. It learns what you teach it, period. So, you can
see that I can teach it biased stuff, which is a concern on people's mind. I can teach it malicious stuff, and it will abide. It's doing its job; it's learning. Don't blame it. Blame the person who trains it. So, that's this side and I'm going to talk about the implication on policies in a minute. So, let's look at the other side, which is using the network. That's a much easier thing. You
have already "frozen" the parameters, so to speak, which means that the parameters now are not knobs that you are adjusting. They are fixed at the combination, the winning combination, that came from the training phase. So, now what do you do? Well, you do nothing. You enter the query, out comes
the answer. It's pretty much you log in to chatGPT, you ask them something, out comes the answer. Not only is it that simple, you can also make any number of copies you want. The training is already done. We know the
winning combination. you want a thousand of them? Make a thousand of them. Very easy to do. If your iPhone has enough memory, you can have your own chatGPT on it. It doesn't cost anything. So now, when you ask the question of how do we regulate AI, there are two categories of regulation. The first one is how to regulate the deployment of AI, the product. Someone
creates a product using AI. What do we do to make sure that it works right? That question is fairly straightforward to answer, because we already have in place the government agencies and the protocols to test the safety of products and approve them or not. FDA does that all the time in order to make sure that the medications and the medical devices we get are safe, what are the side effects, are they effective or not. So if we have an agency like that for AI, products - someone comes up with a product. Let's say I have a neural
network: you put a resume in, and it will tell you whether you give an interview to the person. People have alarm bells about bias, right? Well, very easy. Give me your network. That's what you produced, right? I am going to test it for bias. It's very easy to do. I have a standard data set, and I will see if the decision is biased or not. If
the decision is biased, I'll tell you: tough luck; you are not approved. You have to go back and give me something that is not biased. So, there is nothing difficult about regulating AI as a product. Now, when it comes to regulating the development of AI, that is a different story. So, people liken AI to nuclear weapons. They are so dangerous, and they will kill us all, and we'd better be careful.
And if you look at nuclear weapons, there is a great effort to control them and the way to control them internationally is that you identify a bottleneck, the enriched uranium, and you try to control that because without that people are not going to be able to produce the nuclear weapon, right? So, you try to learn from that and say let's do the same for AI because you just told us that someone malicious can teach AI and we don't want that, so let's control the development of AI, the research in AI that actually produces this system. Well, the GPU which is the chip that is used to train AI systems very efficiently, there are 10 million of them out there already. And that is a conservative estimate.
There is a community which is called open-source community. That's a group of very smart people who openly exchange computer programs and ideas in order to build them without any restrictions. That's a very vibrant community in AI. Any government on Earth, even of the poorest country, can put together the resources to train any AI system that you can imagine.
So, in AI, there is no "enriched uranium". What we have to understand is that AI will achieve its full potential. if you don't do it, others will. There is no escaping that. So, with this in mind. So, where is this going? It's interesting question to ask, because you may have heard, if you read about AI, that even specialists in AI cannot predict where it is going, right? And in your mind, you say what kind of scientists cannot predict how their own field will evolve? What is going on? And the irony here is that it's not that we are afraid of promising and not delivering.
We are actually afraid of delivering far more than we promise. Why is that? Because in the development of AI, we have been very lucky. And I am going to tell you the luck that we had that made the current systems possible, and the luck we are currently having that is likely to make future systems even more impressive. You can call it luck, and you can say that, Oh, we chose the right model and the right algorithm for the right type of problems, so everything should fall into place. It's not luck. OK, thank you.
We will take the compliment. It doesn't matter. However, these really were truly surprising steps from a technical point of view that made what we have today possible. Let me give you the first one.
This is technical, but I think I will explain it so everybody will understand it. Remember the knob? As you turn the knob, you are getting either the function right or you're not getting it right. So, think of the knob as traveling in this direction. Sometimes you are doing poorly, because the lower the better, right? So here, you are doing poorly, here you are doing great, here you are doing OK, and so on. So, the idea now is to be able to take the knob and hopefully get here.
Well that seems like a trivial thing, but remember this is one parameter. We are training 150 billion parameters. So, this is one dimension, this is the second dimension, this is the third dimensional, this is 150 billionth dimension. And this surface is a completely hairy jungle. It's a complete maze. And now, the poor learning algorithm is trying to get to the good value.
The excellent value is here. If we get here, we are done. The good news is that if we even get here, that's good enough. You don't have to go to the absolute best in order to be able to achieve the things we are seeing now. And that is critical, because you can theoretically prove that insisting on getting this, which is called global minimum as opposed to local minimum, that one is intractable.
And by intractable, I don't mean 200,000 years. I mean something that is completely astronomical that will never be achieved regardless of what resources you put together. So, if we insisted on going there, it's hopeless, but this one is good. But we are not sure we'll get there because, look at the algorithm. The
algorithm is looking there and trying to get to the minimum. And because of the nature of the algorithm it's, you know, trying to climb here and, oops, it gets stuck. Now, there are so many of these shallow minima in the surface, that it is very easy to get trapped in one.
So, it could have been the case that when we train the neural networks, we almost always get trapped in one of those, and we don't perform well. However, this doesn't happen. We get to the good guy, and we get very consistently. And if we don't get to it in one try, you can try 10 times or 100 times and you will get there. Now, this is a lucky break because that makes the computation feasible instead of intractable. Even if feasible means a lot
of computation, we still can do it. In this case, we know if we got stuck always, it wouldn't be possible. That lucky break happened as early as the 1980s, so maybe in the 1980s we had a little bit of indication that we are on the right track. Things are falling into place.
The second lucky break is more recent. This is in the last decade. So, the idea here is the following.
You have this neural network, you would like it to recognize pictures, you would like to give this picture and it gives the output. What do you do? We said we are going to train the network in order to be able to achieve this. So, how do you train it? You look at images of different people. Some of them are Shannon, and some of them are not Shannon. you take a small sample, relatively small sample, which is the training data. I'm
taking here just four points, just to illustrate. So, these are pictures of Shannon. These are not pictures of Shannon, and you would like to take that now and tune the parameters here, the knobs, in order to be able to make this network recognize for a given picture whether this is Shannon or not. Now, there is a dilemma. Because here we have, you know, I put here 16 knobs but actually, say, it's 100 parameters. And here, you have only four data points. If you think about it, if you
want to distinguish the Shannon from the non-Shannon, just for this data set, just for the four guys, you don't even need to know what Shannon looks like. You may look for a very trivial artifact in the images that distinguishes these two from these two. So, there will be lots of settings for these knobs, many of them have nothing to do with genuinely recognizing what the person is, that do the job on the training set that you gave. So, you do this and you are likely to be able to get something that is irrelevant.
And I'm giving here an example of just four examples and let's see 100 parameters. This is not really what happens in reality. What happens in reality is maybe we have 40,000 data points to train, and a million parameters to work with. But it's still a million divided by forty thousand that's a huge over-parametrization. There are lots of ways to set this in order to be able to fit the data that you are using for training, which is all the neural network knows, and still not be able to learn. So, the remarkable thing that happened last decade is that you can do over-parametrization over and over and over. Here is a ratio
of like ten, hundred, thousand. You have a thousand more parameters the data. No problem. Somehow, the network can figure out what is the right combination for the real task. Again, you can say is this luck or are we dealing with the right model for the right problems? And people have been struggling with this, the mystery of generalization in deep neural networks. And there are lots of theoretical results trying to justify it. None of them is conclusive.
So, we really don't know why this is working. And if you go to another application, let's say trying to forecast the market, it doesn't work. You overfit so to speak. You end up with something
that is not the function you want. But this is very true for natural things, recognizing images, natural language processing that you have been using, and so on. So, when you put these two guys together. Here is the one with the local Minima. Here is the one with the over- parametrization. It's remarkable they
cover the two main thrusts that we need for learning. Because of this, we need far less computation. if this wasn't the case, we would be computing forever and ever, and never ending. For this, we need far less information.
The data points, the training points - few data points compared to what we theoretically need, which will be a multiple of the number of parameters. And because of this, you can actually have 150 billion parameters and you don't ask for you know 10 trillion trillion examples in order to train. You can train with a much smaller set. And these two guys are the reason why we have the systems we have today.
Again, we will take credit for being ingenious and choosing the right model for the right problems, but from a purely scientific point of view, we don't have an explanation why we are not falling into a bad local minima, and we don't have a full explanation for why we can get away with so few examples and still get the results right. Our luck continues until today. So, I'm going to explain this. This is
very recent. And the idea is that now you are training a neural network, and you have a billion parameters, and then you try 10 billion parameters, 100 billion parameters, and you're trying to see how more intelligent the network can become. So you have tasks in mind. This one is
multi-step arithmetic. This one is taking College exams. This one is, you know, getting a word in context. Let me explain this one so that it's concrete in your mind. If I ask you two questions, "can you cross the bridge?", and then the other question, "can you play Bridge?", you realize that the word "bridge" is completely different between these two sentences because of the context, OK? We have enough parameters in our brain.
However, if you actually try to take a neural network that doesn't have a mega amount of parameters, it doesn't get that part. It cannot recognize the wording context. But remarkably, what happens is that for all of these tasks that are intelligent, you increase the size of the network, nothing happens, nothing happens, nothing happens, and there comes a point and all of a sudden you can do this. Similarly, here. Similarly, here. So this is an emergent ability. If you and your computational ability are such that you are stuck below this point, you can say we will never be able to do arithmetic.
We will never be able to do this. And it takes getting to that level in order to be able to get it. Now, again, we can see this is a lucky break because we really didn't know. We just, you know, had an article first if we go further we are getting close to the brain. The brain can do this thing, so maybe we will do it. And indeed, when you do it, you get these guys.
Now, this is the reason why the scientists cannot predict where AI is going. For all we know, when we increase the number of parameters from the current ones, emergent abilities will happen that are far more than we expect. So, we cannot in good conscience tell you that in two years, we'll be able to do this. In five years, we'll be able to
do this. Maybe, we'll run out of luck. Maybe, it's not going to happen. But the emergent ability is one of the things that are actually extremely interesting even from a biological point of view. Because we realize that humans are far more smart than the other species, and like suddenly we have language, we have this, we have that, so we had emergent abilities and now we have an artificial model that exhibits the same type of thing, and we were able to study it a little bit more quantitatively. Now, if you look at this, and you look at what we were thinking in the 1980s at Caltech, it's rather striking.
These are all papers from Caltech in the 1980s, and there are basically two thrusts for our work. We were trying to be make a bigger and bigger Network because we realized that only bigger networks will get us where we want. So in this case, the usual digital computer at the time was hopeless. You
cannot simulate, you know, a big neural network at all. So, there was an approach to try to implement the neural network directly with electronics. So, we actually have a neuron connected by a synapse, not a simulation of that on a standard CPU in a digital computer.
That was one approach. We even looked for an optical approach, because you can put lots of stuff at a high density in Optics. And we looked at the way to build it this way. So, the idea here is that we were trying to build the hardware that can actually do this. Even the models. This is a former model of neural networks. It's not the one that
we are using today, but you can see in the paper that you are looking for emergent abilities. That's 1980s, OK? This paper remains until this very day one of the top five most cited Caltech papers of all time. The ideas were there. We didn't have the facility to do it, and it took quite a bit of time, quite a bit of work by lots of people, in Caltech and outside Caltech, in order to get us where we want. And it
wasn't only research. Actually, Caltech was the epicenter for computer chips - the design of high density computer chips, VLSI. We were the source, the place to go, when you want to design those. And it's no coincidence that two of our PhD students in the 1980s went on to become long-time Chief Scientists in Nvidia, the company that does the bulk of the hardware for AI nowadays. We founded the top conference in AI in the world, Neural Information Processing Systems, and if you look at the history of it, every breakthrough in AI was presented at this conference over the past 35 years. we even started our own department, academic department, dedicated to this subject. So, all the ingredients were there,
and it took quite a bit of progress by lots of smart people all over the world to get from the seeds to the level we have. And this brings me to an interesting point of contrasting the work in Academia versus the work in Industry. So, this network is what started the current AI Revolution, and it was done by a graduate student in a university. I'm emphasizing the contrast between universities and Industry. This model is what started the Generative AI model revolution, and it was done by a graduate student in a university.
OK, we're talking about the early 2010s. Fast forward 10 years, these are the two biggest breakthroughs in AI recently. This one is AlphaFold, which solved pretty much completely the protein folding problem, a formidable problem in Biochemistry that has lots of applications including medical applications. And we were making pathetically slow progress using the traditional methods, and comes AI as a bulldozer, takes over, solves it all, and now you have thousands of proteins, if not hundreds of thousands, that you can go from the amino- acid sequence to the folding of it. This was done by DeepMind which is attached to Google. OK.
ChatGPT, which is very famous, this was done by OpenAI which is attached to Microsoft. There is a reason. Actually, DeepMind itself said when it was acquired by Google that they wanted that because that was the only way to have access to computational resources that can make them run at the scale that gets them the results. OK.
And openAI had a sort of a funny quote when they said the computational costs that we have are eye watering. So, it really is a pretty serious business beyond the realm of possibilities, by more than two orders of magnitude, from the academic grants you can get. So, it's no wonder that this is happening in Industry. By the way, hats off to DeepMind and to OpenAI. I have colleagues there that I know personally, and I have great respect for.
I am just lamenting the fact that the great talent in the top universities, which typically brings the state of the art in all the sciences and technology, are handicapped by the resources. We try to do something. I work on medical applications because it doesn't take that much computation. Well, "it doesn't take that much computation" is relative. It takes tons of computation,
but at least I can do it. There are colleagues who team up with a company because that is the way they will get resources. but if you want to have academic development of the field of AI, especially for something like emergent behavior which you cannot study at all until you get to the right scale, something needs to change. And I have a suggestion. There used to be an initiative at Caltech, it is still there. It's a Caltech-MIT initiative called LIGO. You
heard that before, right? That was the mega project that ended up detecting gravitational waves, and ended up in a Nobel Prize. Was a great scientific achievement, and it was extremely costly. But that was the only way to do that project. I believe that now in AI, we are in a situation where we need something akin to LIGO in order to get the great talent in Academia to work on the forefront of AI, without any commercial agenda, just knowledge. And not only for the technology that is going to be achieved. As I mentioned,
there will be feedback for biology, because if you look at the change in 10 years from the time it was done in Academia to the time it was done in in Industry: When it was done in Academia, we used less than 100 million parameters. The recent results are more than 100 billion parameters. Another jump like that, and we are at the scale of the human brain, a feat that we could not have imagined. So, there is a lot of natural science that actually can be investigated if we are free to investigate this fully. OK.
So, now I'm going to go to the upside. And I'll try to be quick. I'm taking more time than I planned, but it's a very important subject. And when you look at the upside, there are two things AI achieves. Things we already can do, and things we cannot do.
And I will show you examples in a minute, but if you look at this and say which one would be more impressive? If you look at this, of course it will be more impressive to do the things we cannot do, because we cannot do them. It turns out that all the attention, and all the excitement, is about the things we can do. OK. Perhaps because this infringes on our sense of uniqueness. Maybe because it threatens our jobs. If you are doing something that we cannot do, no job will be taken okay, so go ahead, good luck.
While a lot of achievement is done here, and a lot of achievement is done here, so I'll give you examples. This is a simple example, driving a car. You can all drive cars. If you get self-driving cars, we are
replicating what we have, and I will go into more details about that. The things we cannot do are pretty impressive, and I'm going to focus on medical applications because I feel that they are underreported. There is a great amount of progress in the application of AI to medical application that will affect our lives.
So, this is a project in the lab of my Caltech colleague Professor Yang. What you are looking at is a biopsy slide under the microscope, and the goal is to look at this and decide whether this type of cancer will spread or not. You go to the human experts, and you ask them to look at this and tell you, and they absolutely can do nothing. Their opinion is as good as a coin flip. You go to AI, and you train it, and it achieves a performance close to 90 percent.
You go back to the human experts, and tell them this is what AI did, can you now look at it and tell me what is going on? They can do nothing better than a coin flip. Remember the explainability thing? The subtlety that AI is picking out of this is just beyond the ability of the visual system to detect. Medical applications of AI are what I am focusing on nowadays, and I'm focusing on them for a good reason. If AI does nothing but the medical impact, it will have earned its keep.
This is something that will affect our lives profoundly, our quality of life. And although it is not as celebrated as the more flashy applications nowadays, down the road it will affect your life more than the other applications will. But let's go to the things that we can already do and try to understand it. Because they are affecting jobs, they have social impact, and the best way to look at them is to compare them to a previous incarnation of progress: the Industrial Revolution. So it used to be that we would relieve manual labor by having machines.
OK. Now, this was so big that this is the second major turning point in human history, comparable only to the advent of agriculture, which was the first one. Changed everything in our lives.
Now, we go to the AI Revolution. We are just relieving mental labor. Instead of relieving this muscle, we are relieving this "muscle". OK. And you get this.
And now, when this takes hold, this will cap the digital revolution as the third major turning point in human history. It's a big deal. So, what lessons can we get from the Industrial Revolution to the AI Revolution in terms of societal impact? There's a key difference between the two, and the key difference is the pace.
Industrial Revolution took about 80 years to take full hold. That's the lifespan of a person, actually at that time in history, it was more than the lifespan of a person. So people have time to adapt. People look at their parents: it's getting out of trend, maybe I should go into something else. There is time to adapt.
This is just happening too fast. 20 years is even a very conservative estimate. It's probably 15. And therefore, things are happening very quickly. So when you look at this, so what
do we do? Well, there are two aspects here. So one suggestion is: wait, wait, wait a minute. This is happening too fast. Let's put hold on the development of AI systems maybe for six months until we figure out what is going on. You probably heard about the petition that was going around. While well intentioned, this is in my opinion completely ineffective. If you put a moratorium on the development of AI, the good guys will abide by it and the bad guys will not.
So, all we are achieving is giving the bad guys a six-month head start on us. That's not the way to go. The other aspect is in terms of society. There is no question that there will be loss of jobs, and there will be a lot of turmoil because of it. And we need to have a safety net that will take care of that. Think of AI as something that will pay off big dividends. For sure it will, but
it has growing pains. And the people who are living now are going to suffer the growing pains more than the fruits of AI. And we should be very much aware of that, and we should have the safety net in place to be able to retrain people, to be able to take care of people when they get displaced, because this is going to happen at a very large scale. And if you ask me what are the industries that are affected, pretty much everyone. First, I say by the year 2030. chances are it could be by the year 2025, but let's say 2030. And I am
saying that AI will automate anything that requires routine intelligence. It probably will be able to replace stuff even smarter than that. Routine intelligence is the term I give for things like, you know, driving a car, answering the questions of a customer, things that require intelligence but are not that sophisticated. Everything of
that realm will be replaced. So, there is an interesting dichotomy here. In history, if you look at it, technological developments usually affected the manual labor. Instead of lifting stuff, you have a machine that lifts the stuff, so you help the person who was lifting it. Now, AI is affecting office workers, and even affecting scientists.
If you look at protein folding, the problem that I had, people were working on this. They have an established discipline, they have an annual conference, they have a competition every year to see where is the state of the Art. And they have all kinds of sophisticated ways of doing this. Comes AI and completely beats them. Completely. And the initial reaction of scientists is rejection, resentment, we don't trust it. And you can look at
history, some of the quotes that were said, it was really funny. And this happened in more than one discipline where AI took over from that. But eventually, people realize that if you can't beat them, join them. And now everybody who does research in protein folding does AI. Computer Vision is a branch of AI. And so on. So because of this, Caltech has a program, an instructional program, to be able to teach research workers in different branches of science the practical aspects of AI that can help them in their work.
Do you know what the program is jokingly dubbed? No scientist left behind. [Laughter] OK, let's go for the downside, and call it a day. There are risks of AI and I singled out and grouped the malicious use of AI. Rogue AI system, which I will elaborate in some detail because it's an existential threat that is being debated in the press. And then the social impact. So the malicious use of AI is completely clear in people's mind.
You know there is hacking and scams, so we already suffer from those. And people are wondering how do we legislate now that AI is there? What do we do? So, I have only two observations. First, the cybercrime, or digital crime, is growing even without AI. So clearly, law enforcement is not catching up with the crime. So, we may be looking for laws, but it may be that what we really need to do is beef up the law enforcement in order to be able to cope with the incoming tsunami of these crimes when they are enabled by AI. If you think you have seen hacking, wait until AI comes in and you have hacking on steroids.
We all have seen recently, just a couple of days ago, the fake picture of an explosion near one of the buildings, and that completely rocked the stock market until people realized that it's false. So, there is a lot of legislation that needs to be done, and the legislation will be cat and mouse, legislators and bad guys. And different types of crime, we don't know what the different types of crime. But I have one suggestion in terms of legislation that may at least put the brakes on the explosion of these crimes in the coming years until we figure out what exactly tailored legislation towards serious crime can be done. What I suggest is to make the use of AI in a crime an "aggravating circumstance".
Let me explain what that is. Carrying, a gun in and of itself, is not a crime. However, if you commit a robbery, it makes a lot of difference whether you are carrying a gun or not. It's an aggravating circumstance that makes the penalty go up significantly. And it stands to logic, because now there is more threat, maybe you are emboldened by it so you are going to do it, and what not.
So when I say that the use of AI in a crime would be an aggravating circumstance, you are not creating any new crimes. You are just telling people that if you commit a crime, and in the course of doing that you use AI, your penalty will be much stiffer. This will be a blanket legislation that can be done that at least will put the brake on what is going to happen very soon.
OK. Now, we go to this fellow which is more interesting. The Rogue AI. AI will take over. It's going to
kill us all, and so on. And in some sense it's funny because basically, we are afraid that AI will do to us what we have done to other species. And there are many scenarios for this. They are more intelligent than us.
They will take over. We'll be subordinate. Some people even say the scenario is even more sophisticated. It's not the AI system that we build. Because they are intelligent themselves, they are going to design better computer chips to train better AI systems and get more intelligent. In turn, will do more
and it's a spiral up and we'll be completely marginalized. So, this obviously is an existential threat for humanity, if you believe it. OK. So, when it comes to that particular threat, I respectfully disagree. And I'm going to explain to you why I disagree. There are three points, three issues with the argument that were raised of AI's going to take over. One of them has to do with desire.
Does AI really want to take over - if AI can "want" anything. The other one: even if it wants it, is it able to do it? And then finally the question: is intelligence the same as dominance? So, let's just take this one at a time. The fallacy here is that we are not used to dealing with anything intelligent, other than humans. So all of a sudden you talk to chatGPT, and it makes a lot of sense, you think of it as a human. Maybe it has feelings, maybe it has consciousness, and in general we attach the other attributes of humans to that thing. So, that thing is
intelligent, then it definitely wants to dominate, it wants to be bigger, like humans do. However, we need to realize that intelligence is an ability. Dominance is a desire. And it's built in us for biological reasons. This is a good way to survive. This is a good way for selective procreation, and so on. It
is not related to intelligence per se. So when we look at something intelligent, and we put the other attributes of humanity, then we can really worry it's going to take over or not. But the question is: is there really a desire for a purely intelligent system to do that? The other one is the ability. So I gave you the scenario of AI taking over, and the problem with this is that you ignore the logistics. So now AI
is going to build better chips and train better neural networks. How is it going to do that? I'm running a guy on my computer. Where is it going to get the material, and the fabrication, in order to be able to build the chips? And then these chips - for example, something like chatGPT requires thousands of those guys, which are extremely energy hungry, that run for two months solid before they get the results. So is AI just going to will this to happen, while we are standing by looking at this and we can't even pull the plug? I'm sorry. I don't buy the argument. The third one which has basis in science, which I'm going to talk about is the question of intelligence versus control.
So, there is a question of being Machiavellian. So you want to dominate others, and this and that. So the question is: is being intelligent correlated with being Machiavellian? Well, general intelligence and Machiavellian intelligence - Machiavellian intelligence is actually a thing. Machiavellianism and Machiavellian intelligence is a thing in Psychology and Biology. They have been studied. And the idea of general intelligence is - it's a vague notion, but there are many measures of intelligence. IQ, sometimes you are
a better strategist, etc. So there are certain attributes that you can measure quantitatively, and the good news is that these guys are positively correlated. So, if you are more in one, you are more likely to be in the other. So, the common core is what we are referring to as general intelligence. That's a good notion, so now the question is: is that general intelligence related to Machiavellianism or Machiavellian intelligence, the desire to dominate and the ability to dominate, and what not? So, there is not much in terms of quantitative literature on this, but I'm quoting a paper that is a review paper that is highly cited. And this is what it does. So, it looked at
different tests and there's a measurement of general intelligence or particular aspects of intelligence, and measurement of Machiavellianism and it's trying to say are they correlated or not. And the conclusion is: general intelligence has no correlation with Machiavellianism. So if we think humans are - they want to dominate and they are intelligent at the same time, these are just independent ones. And if you want a striking example
of this, here is a picture taken on campus here at Caltech of the pinnacle of intelligence who is as humble and peaceful as can be. The two traits are simply not related. If you are worried about AI being used maliciously to to hurt us, I am with you 100 percent. But if we are talking about AI, on its own, going rogue and hurting us, I am not worried about that.
I will tell you what I'm worried about. The
2023-06-02 16:31